Leave a Comment
Microservice architecture patterns
Table of Contents
Why do you need a microservice architecture?
Decrease blast radius of problems and increase flexibility.
You want technology diversity in your company.
You want to scale your app more granular according to consumer needs.
You want newcomers to be productive earlier.
You want your company structure to be mirrored with technical responsibilities (it’s mainly about SOA in general, not only about microcervices; more on that).
What is a microservice oriented application
It is a set of small loosely coupled services, which communicate with each other through some protocol (defined in a policy).
Each service has its own storage (DB) and can be developed and deployed independently.
Problems
While making your service simpler, this approach makes your entire application architecture more difficult.
You have to deal with partial failures, slower responses caused by more network interactions.
Cross-service features are harder to develop and release.
The major problem is data consistency problem. When you have to store some change (commit a transaction) in multiple services (like order service and user account service).
Significantly increased employee amount.
Patterns
(picture taken from Microservice architecture)
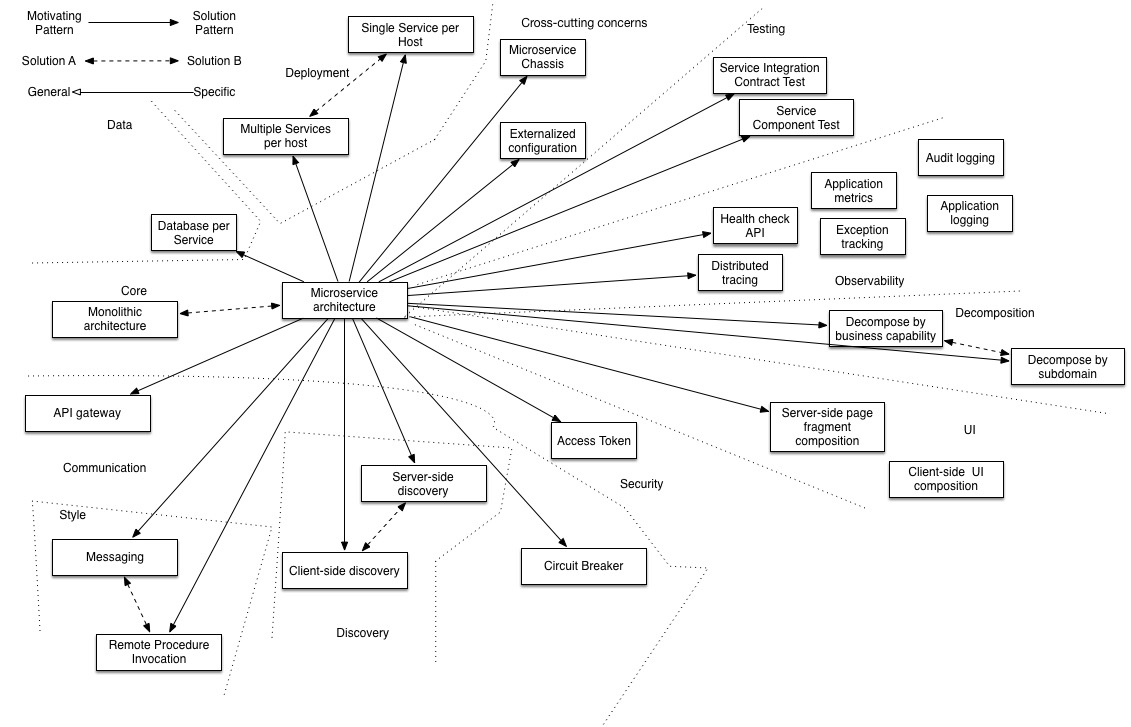
The most important are:
- Split services by business needs
- Database per service
- (Server side) service discovery
- Framework for faster development, unification and standards support
- Log aggregation (with graylog)
- Application metrics (prometheus+grafana is a good thing)
- Distributed tracing (like opentracing and jaeger)
- Healthcheck API (framework+kubernetes, for instance)
Full list:
- Decomposition patterns
- The Database per Service pattern describes how each service has its own database in order to ensure loose coupling.
- The API Gateway pattern defines how clients access the services in a microservice architecture.
- The Client-side Discovery and Server-side Discovery patterns are used to route requests for a client to an available service instance in a microservice architecture.
- The Messaging and Remote Procedure Invocation patterns are two different ways that services can communicate.
- The Single Service per Host and Multiple Services per Host patterns are two different deployment strategies.
- Cross-cutting concerns patterns: Microservice chassis pattern (framework) and Externalized configuration
- Testing patterns: Service Component Test and Service Integration Contract Test
- Circuit Breaker
- Access Token
- Observability patterns (alerts, metrics, logs, traces):
- UI patterns:
Event sourcing for data consistency across microservices
You should want to atomically update data in several microservices. For example, you want to decrement user’s account on order event.
You can try to use Event sourcing
It is when you store all state-changing events for your entities. In this case, entities are like a state machine but any state can be rolled back to the previous one.
And to recreate the entity’s state, you have to replay all the log. To make this operation faster, the application makes snapshots from time to time.
CQRS for retrieving data in applications with event sourcing
CQRS stands for Command Query Responsibility Segregation.
If you have a storage of state-changing events for your entities, it’s really hard to retrieve a list of all the entities in some state, or entities with some attribute.
To solve this, you can have a separate database, which is used only for querying and is populated with data based on system events. So, it subscribes to all events related to needed entities and represents a current state of the system (like a DB view).
Further reading:
Microservice architecture
Event sourcing
CQRS
LEAVE A COMMENT
Для отправки комментария вам необходимо авторизоваться.